General Theory of Music by Icosahedron 1 を雑に読んでみた
「正二十面体の頂点 12 個に 12 個の音をうまく配置すると、正二十面体が持ってる基本的な性質によって西洋の音階の様々な性質が説明できる」というツイートで話題になった arXiv 論文を雑に読んでみた。
数学、音楽クラスタのみなさま!うちの弟が「正二十面体の頂点12個に12個の音をうまく配置すると、正二十面体が持ってる基本的な性質によって西洋の音階の様々ん性質が説明できる」という論文を発表したのですが、難しすぎてよくわからないので、誰か解説してください…https://t.co/tFHxdZzDwF
— 今井峻介 (@imaishunsuke) 2021年3月21日
友達と一緒に書いた論文が掲載されました。https://t.co/Hom6f45Xey
— 今井悠介 (@Yusui07579536) 2021年3月21日
正二十面体という古代ギリシャ時代から知られている美しい立体によって
西洋で用いられてきた様々な音階が結び付き、そして美しい和音が黃金比で表されるという論文です。
論文は以下の arXiv。
免責事項
- 本ブログの筆者は音楽の専門教育を受けていません(学部の電気電子工学をバックグラウンドに持つ webdev です)
著者は?
- 名大物理・日本ケミコン・ヴュルツブルク音大
- 楽理なのに議論の随所にパリティや群論絡みの話が出てくるのも納得
何を主張している?
- 音階を表現できる正二十面体 "musical icosahedron" を提案(以下 MI と略記)
- 半音階と 1 つの全音音階を表現する MI から出発して、以下を示せる
- MI 上で向かい合う 2 音はトライトーンを形成すること
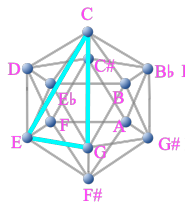
- 任意の長・短三和音を、1 つの MI 上における黄金三角形で表現できること
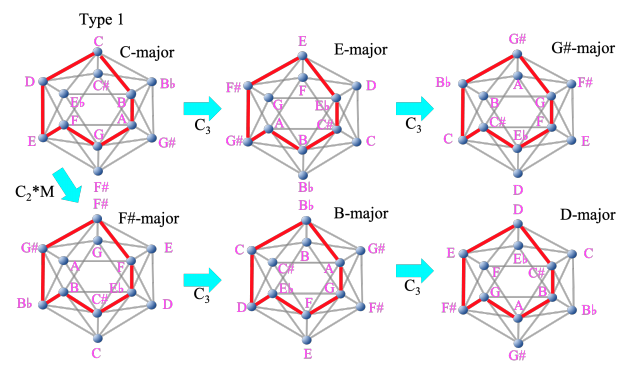
- 任意の長・短音階どうしの関係を、2 つの MI を用いた回転・鏡映操作で表現できること
- 長・短音階と教会旋法との関係を、MI における反転操作で表現できること
- 長・短三和音を「MI 上の黄金三角形で表現できる三和音」として一般化
- 長・短音階を「MI 上の回転・鏡映操作によって長・短音階と一致する音階」として一般化
先行研究に対する批判は?
- 無調音楽やその理論は「人工的」で、数学的なもっともらしさは見られない
- その他、具体的な論文を引用した批判はなし
提案理論のキモは?
- MI の各頂点に 12 音を 1 つずつ当てはめる
- 辺を共有して隣接する頂点には「音階」の隣接音を置く、という条件を課す
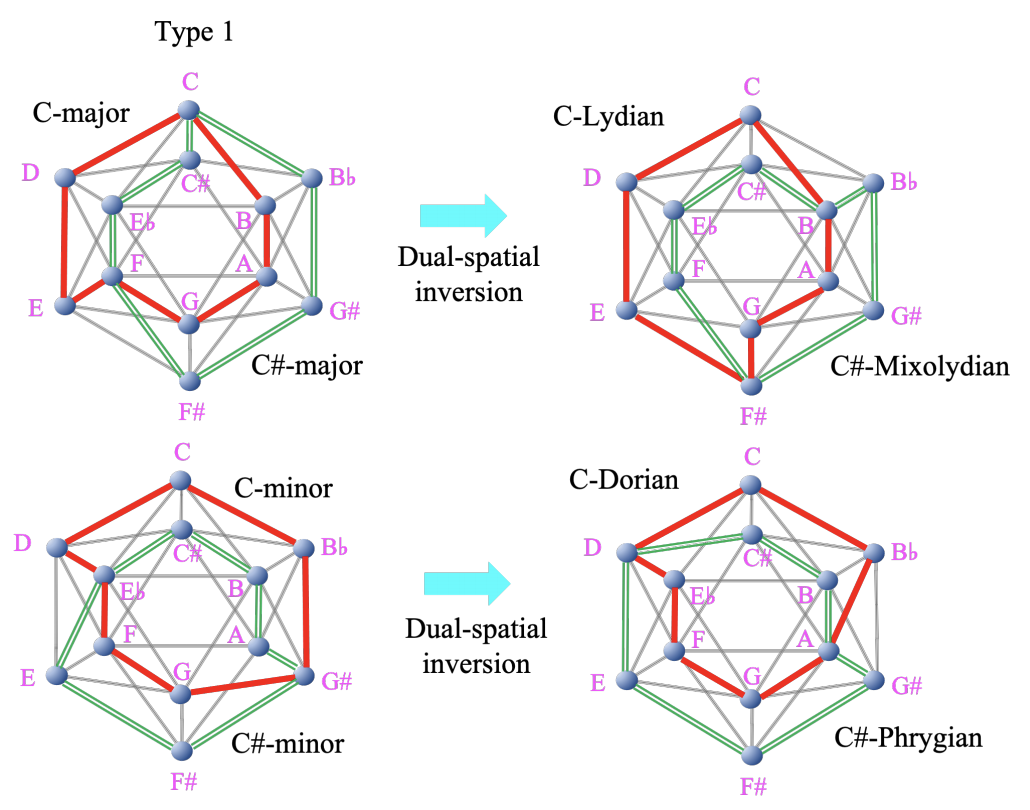
- 半音階と 1 つの全音音階を表現できる MI は(回転・鏡映対称を除いて)以下の 4 つだけ
- 注:3.2 の最終段落で「Type 1 の各音を半音上げると Type 3 になる」みたいに書かれているが、Type 4 になるのが正しそう
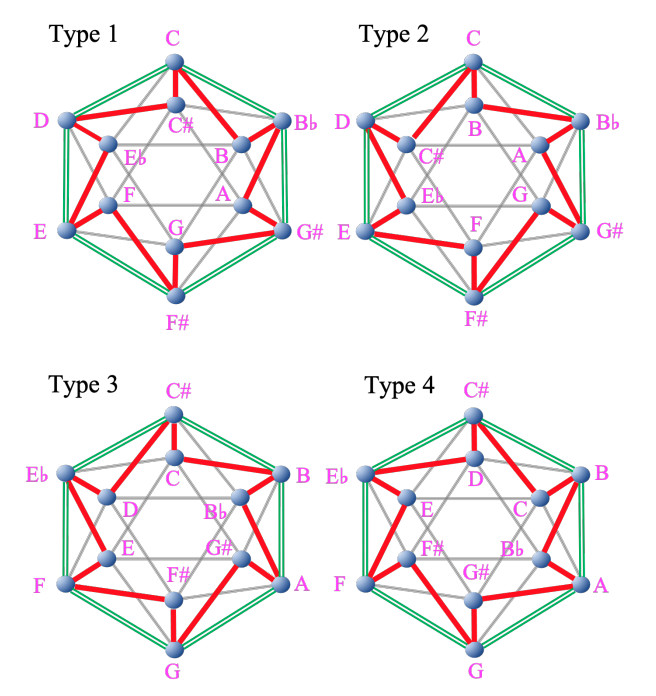
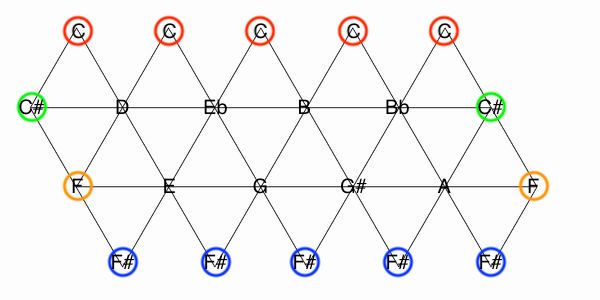
- 注:展開図を使って、隣接の条件を満たすように音を埋めていくと納得できそう
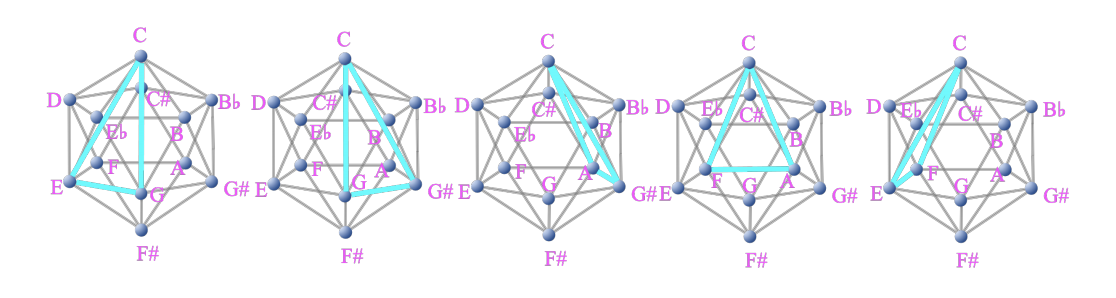
- 長・短三和音を構成する 3 音を MI 上で結ぶと、黄金三角形が現れる
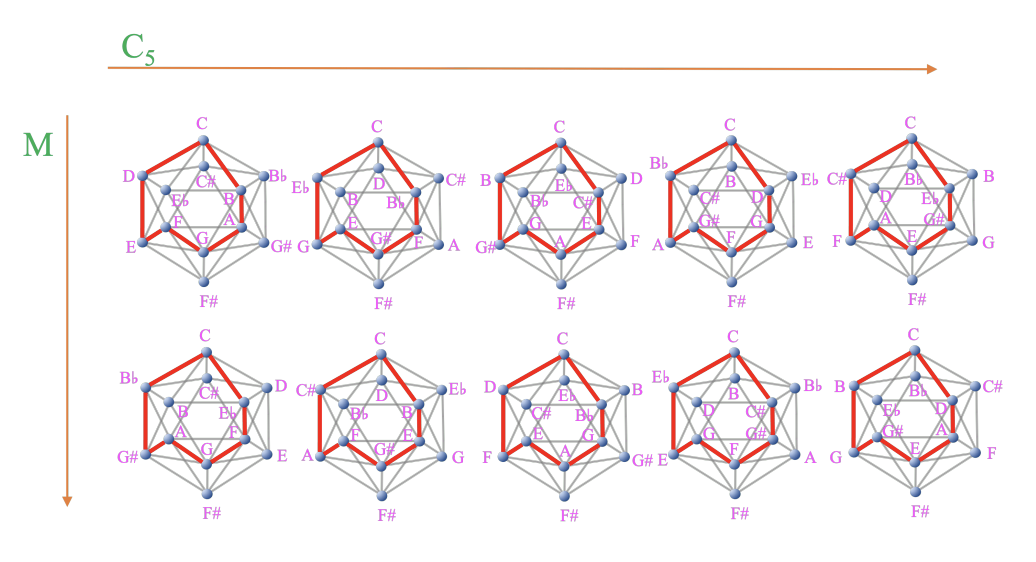
- MI 上の頂点を特定の経路(経路を辺に限定しない)で結ぶと、MI を回転・鏡映操作しても同じ経路が長・短音階になる
- 注:図中の C2 は周期 2 の回転操作、C3 は周期 3 の回転操作、M は鏡映操作
- MI 上で反転操作を行えば長・短音階の経路と教会旋法の経路に類似性が見いだせる
- 注:ここでの「反転操作」は、おそらく原点中心に各点の xyz 座標の符号を反転させることだと思うけれど、まだ Figure 20 の主張を紙の上で再現できていない……。
- 長・短三和音を「MI 上の黄金三角形で表現できる三和音」と一般化
- 長・短三和音は 12×2 通りに対して、MI 上の黄金三角形は 60 通りある
- 例えば C Major の △CEG を周期 5 の回転操作で一般化
- 長・短音階を「MI 上の回転・鏡映操作によって長・短音階の経路と一致する音階」と一般化
- 周期 5 の回転操作と鏡映操作で 10 通りの「音階」が得られる
- 周期 5 の回転操作で一般化するのは、三和音の一般化と共通性がある
- Type 4 の MI を使っても一般化が可能
- 注:図中の C5 は周期 5 の回転操作
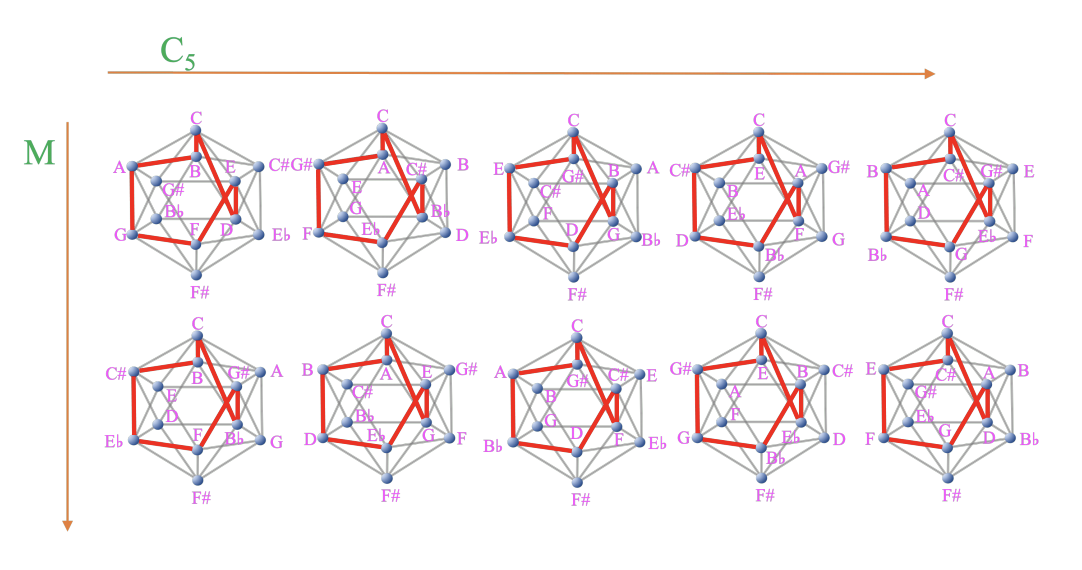
議論はある?
- 聴覚的な議論に依拠することなく、純粋に数学的な議論のみで展開できている
- 半音階 & 全音音階からスタートせずに、メシアンモード(移高の限られた旋法)からスタートしたらどうか
- 他の多面体、または他の次元で考えるとどうか
個人的な所感
- 自分が思うに、この論文の話題は
- トライアドやスケール間の対称性
- そもそもトライアドやスケールとは何か
- 前者については、群論で議論を発展させた方が良いかも?
- 単にトライアドやスケール間の対称性が完全正二十面体群と同型なだけ?
- MI 上での対称性を議論するときに、無視されている頂点が一定数あるので、群の位数はもっと落とせるかも?
- 後者については、なかなか判断が難しい
- 三和音や音階の「経路」が必ずしも正二十面体の辺ではない(立体内部も通りうる)のは、そもそも数学的に美しい?(メシアンモードからスタートすれば別の結論が出るのかもしれない)
- 正二十面体という対称性の良い立体を選んだことで、色々な偶然が重なっている?
- トライアドやスケールとは何か?という問いについては、部分群やグラフ理論の議論で発展させるべき?
- 「工学的」にはコード進行の可能性だったり、与えられたコード上で選択できるスケールの可能性を、理論から示唆できる方が「嬉しい」はずなので、楽理って難しい(おわり)
宣伝
野良の日曜楽理屋が集う Discord サーバー "Gacrian" を建てています。
楽理にまつわる本の輪読も最近始めました。
ROM 専含めて興味ある方は以下から是非 ✏️
午前起床は何時起床なのか
導入
しばしば Twitter では「午前起床」というツイートが観測される。しかし、それらは午前ではなく午後にツイートされることも少なくない。
そこから「午前起床とは何時起床なのか」という疑問が生じるのは極めて自然なことであるが、これを実際に調査した文献は筆者の観測するところ未だ無いように思われる。
したがって本エントリでは、Twitter から「午前起床」ツイートの実データを収集し、分析・調査するものである。
データセット
Twitter API 経由で「午前起床」を含むツイートを検索し、12/4 ~ 12/12 における 139 ツイートを収集した*1。
query = f'"午前起床" since:{since} until:{until} -RT -filter:replies' # https://developer.twitter.com/en/docs/twitter-api/v1/tweets/search/api-reference/get-search-tweets result = api.search( q=query, lang="ja", tweet_mode="extended", result_type="recent", count=100, # up to a maximum of 100 )
データを眺めてみたところ、bot や Q&A サービスの自動ツイートが散見された。
【バトロワ時報】ウ「朝だ!」う「うんまぁ13時だけどな」ウ「…俺が起きたその時間からが昼だから午前起床だし」う「涙拭けよ」
— リア友バトルロワイヤル (@RBR_memo) 2020年12月12日
みんなからの匿名質問を募集中!
— 棒棒棒ー棒・棒ー棒棒 (@stickking4) 2020年12月9日
こんな質問に答えてるよ
● さっさと関東来いや…
● どうやれば午前起床出来ますか?…#質問箱 #匿名質問募集中https://t.co/mH4KbEviBp
これらをデータセットから除去するため、ルールベースの前処理により最終的に 126 ツイートを得た。
分析結果
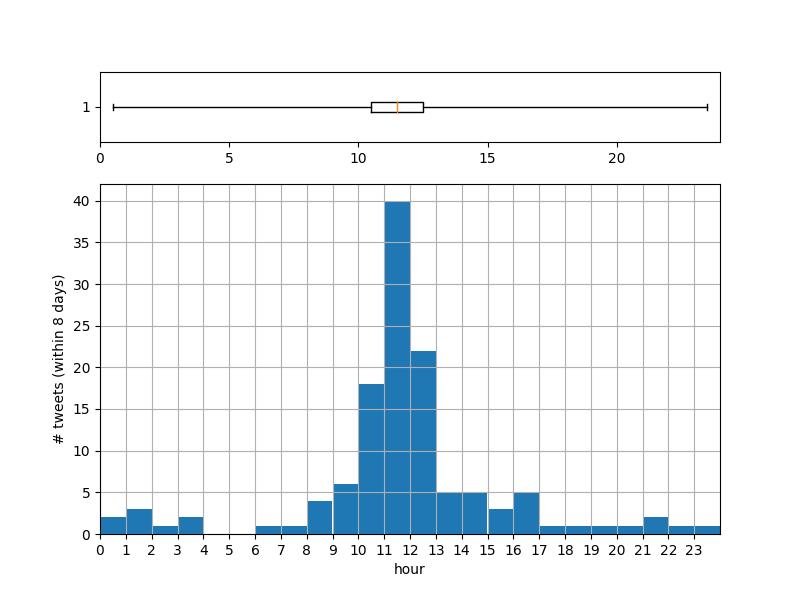
ツイート時刻(N 時台)とツイート件数でヒストグラムを描いた図を以下に示す。
考察
上図より、中央値とピークは午前 11 時台であり、午前 10 時台 ~ 午後 12 時台 の「午前起床」が全体の約半数を占めることが分かる。
実際のツイートを眺めてみると、午前 11 時台の「午前起床」は滑り込み成功を喜ぶツイートが、午後 12 時台の「午前起床」は失敗を悔やむツイートが多く見られた。
ヒストグラムから気になるのが裾の端にあたる部分であるが、具体的にツイートを見てみると、午前深夜帯の「論理明日は午前起床するぞ」という宣言系ツイートや、夕方以降の「今日は午前起床で疲れた」という報告系ツイートが含まれていた。これらのデータ除去は今後の課題とする。
4時に寝て午前起床を目指す
— 早寝早起き 金曜に歯医者の予約 散髪 (@_mapsto) 2020年12月6日
午前:起床→コーヒー→仕事
— しりうす (@sirius_general) 2020年12月6日
午後:掃除→散髪→買い出し→風呂
ここまでで割とへばってきてるけど、まだ料理とゴミの片付けと仕事が残ってるのだ...
午前深夜帯や午後深夜帯におけるその他の「午前起床」には、ツイッターに住まう「本物」が濃縮されており、本エントリでは割愛する。
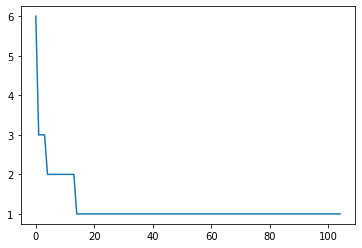
また「午前起床」のツイート数を screen name 単位で数えてみたところ、一部のユーザーが頻繁に「午前起床」していることも見て取れた(実際のツイート時刻についてはお察し願いたい)。
まとめ
日本時間 13:00 までに起床できたならば、あなたは日本の Twitter ユーザーのうち上位 75% の午前体内時計で生活できているものと結論付けられよう。
しかし、個々人が独自のタイムゾーンを有している場合はその限りでない。
皆さん良い起床を。
*1:無料枠では 1 週間分のデータしかアクセスできないため。有料プランを申し込む、または継続的にクロールすることでデータセットをより増やせると考えられる。
sync.Pool と unsafe.Pointer は混ぜるな危険
Go で書いた API サーバーでなかなか不思議なバグに遭遇したのでメモ。
バグの発生状況をできるだけ簡単化して記述すると以下の通り。
func handleFoo(res http.ResponseWriter, req *http.Request) { var bytes []byte = fetchBytes() // ライブラリ使用 foo := *(*string)(unsafe.Pointer(&bytes)) callExternalAPI(foo) // 外部 API 呼び出し renderJSON(res, foo) // foo を JSON に整形して返す }
この API レスポンスに含まれる foo の内容が確率的に壊れる。
バグの起きたレスポンスを見るに、何かメモリが壊されているような雰囲気は察したので、unsafe.Pointer 周りが怪しそうな予想を立てつつも、元となる []byte はリクエストの goroutine 毎に独立なはずだしなあ、と悩む。
当然ながら、外部 API を呼ぶ際に foo が壊されているのかもしれないと疑うも、
- 外部 API を呼ぶ前にレスポンスを返すとバグは起きない
- 外部 API を呼ぶとバグが起きる
fooの代わりに任意の string を与えてもバグが起きる
となり、さながら ハイゼンバグ かとさらに悩む。
さらに調査を進めると、ライブラリを使用している fetchBytes() の中身もさらに怪しくなってきた。これも説明のために簡単化して書くと、
var pool sync.Pool func fetchBytes() []byte { parser := pool.Get().(*Parser) // 何らかのパーサー defer pool.Put(parser) parser.Parse() // 何らかのデータをパースする return parser.GetBytes() // []byte を返す }
事実、この fetchBytes() は他の API でも使われており、sync.Pool ということは一度アロケートしたメモリ領域を可能な限り使い回す意図だから、ここに何かヒントがあるのでは……? と思い、Parser の中身も調べると、
type Parser { cache []byte } func (p *Parser) Parse() { var data string = someString() p.cache = append(p.cache[:0], data...) } func (p *Parser) GetBytes() []byte { // 説明のため簡略化 return p.cache }
これで今回のバグの原因が明らかに。まとめると次の通り。
- 問題の API が叩かれ、
Parserの保持したメモリ領域上(cache)にデータが読み込まれる unsafe.Pointerを使うため、fooの string はParserの保持するメモリ領域上を指す- 外部 API を呼んでレスポンスが返ってくるまでに、一定の待ち時間が発生する
- この待ち時間に、同じく
fetchBytes()を呼ぶ他の API が叩かれる(別スレッド・別 goroutine) - sync.Pool から取り出した Parser が 1. と同じものだった(既に
pool.Put()済みだった)場合 Parserのcacheはp.cache[:0]でクリアされるだけなので、同じメモリ領域上に別のデータが展開される- こうして最初のスレッドで処理されていた
fooは意図しないデータを指してしまう
もちろん、実際のコードはさらに複雑で、fetchBytes() とお茶を濁していたライブラリは valyala/fastjson だったりする。
今回の場合、そこまで大きいデータを扱っているわけでもなく、[]byte → string 変換が何回も走るわけでもないので、単純に string(bytes) で明示的なコピーをするよう修正して事なきを得た。
過度なパフォーマンスチューニングは YAGNI だと再認識。
TIL: Go の sync.Pool と unsafe.Pointer 混ぜるな危険
— Hash / Ryo Kato (@hashedhyphen) 2020年5月12日
PR
私が Lead Engineer を務める Qufooit では、Go・k8s を中心にサーバサイドエンジニアを募集しています。私たちと一緒に世界へ通用するサービスを開発しませんか?
Bolt 製 Slack Bot で app_mention イベントに反応させる
Bolt のチュートリアル には app.message() しか取り上げられていないが、app.message() だと app_mention イベントに反応させることができない。
Bot 宛のメンションにだけ反応させたいとか、スコープを app_mentions:read だけに絞りたいときに、わざわざ message イベントまで subscribe する必要があって不便。

実際にはこんな感じに書く必要がある。
giste25c64094a3738d2efb42459f26fcd06
解説
app.message() やその前後のソースを眺めてみると、実は message イベントしか subscribe されていないこと、本質的には app.event("message", matchMessage(pattern)) の alias だということが分かる。
https://github.com/slackapi/bolt/blob/455bf5849708c8cea4f0683ca45d900c29f97535/src/App.ts#L312-L327
matchMessage(pattern) もソースを追いかけてみると、pattern に合致した post のみ通過させるフィルタを作るヘルパー関数だと分かる。ただ実際に import して使ってみると分かるが、何故か app_mention イベントに転用できない(微妙に型が違う)。
なので、上記のように matchMessage() と似たようなフィルタを自前で書きつつ、app.event("app_mention") でリスナーを登録してあげればちゃんとメンションを聞ける。
めでたい。
余談
とはいえ書き味が少しだるいので、もうちょっといい感じに書ける API 欲しいなーと思って Issue だけ立ててみた。同意得られたら PR 送ろうと思う。
2020-05-28 追記:PR が master にマージされた。